吃瓜简评
### MemPalace AI记忆系统:结构化记忆的未来,#### 项目概述,MemPalace是一款由Milla Jovovich和Ben Sigman共同开发的开源AI记忆系统,旨在通过结构化的“记忆宫殿”模型提升AI的记忆管理效率和准确性,该项目在GitHub上迅速获得了广泛关注,展现了其在AI领域的潜力。,#### 核心亮点,1. **高效检索结构**, - **层级化结构**:将知识分为大房间、主题房间和具体记忆,类似于人类的记忆网络,提升检索效率约34%。, - **主题和属性**:通过“走廊”定义记忆类别,并为信息打上属性标签,增强语义约束。,2. **本地化与隐私保护**, - **本地运行**:所有记忆处理在本地完成,避免了数据传输的隐私风险。, - **数据管理**:支持多种数据模式,如项目文档、对话记录等,确保数据按需处理。,3. **语言压缩与准确性**, - **AAAK语言**:通过简化语言减少token数量,节省资源,但需权衡精度,AAAK模式召回率为84.2%,RAW模式为96.6%。, - **实时纠错**:集成fact_checker.py,保障信息一致性,避免生成错误。,4. **灵活部署**, - **简单安装**:通过pip安装和命令初始化,适合普通开发者使用。, - **多种模式**:提供自动模式和手动增强模式,满足不同使用需求。,5. **团队背景与未来展望**, - **跨界团队**:由演员和程序员组成,展示了多领域协作的优势。, - **开发动机**:Milla Jovovich的跨界项目体现了AI在信息管理中的潜力,未来可能扩展更多功能,如知识图谱和跨项目联结。,#### 挑战与展望,- **信息管理**:处理主题关联和信息碎片化,需优化查询效率。,- **准确性权衡**:AAAK语言可能影响信息精度,需根据具体需求选择。,- **社区支持**:快速前端开发表明社区热情,未来可期。,#### MemPalace凭借其创新的记忆结构和开源特性,在AI记忆管理领域展现了强大的潜力,其结构化的设计和本地化操作使其在隐私保护和效率提升方面具有优势,未来有望成为AI应用的重要工具。**MemPalace:《生化危机》女主开发的AI记忆系统**,**,MemPalace是一款由Milla Jovovich和Ben Sigman开发的开源AI记忆系统,灵感来自古希腊的“记忆宫殿法”,该系统以房间和主题为单位,结构化地管理和检索信息,显著提高了AI的记忆效率。,**核心特点:**,1. **结构化记忆管理:** 将知识组织在“宫殿”中,每个房间代表主题,每个房间内存储具体记忆点,信息按主题和属性分类,便于检索。,2. **高效检索:** 通过分层结构缩小搜索空间,提升检索效率约34%,在长期记忆测试中表现优异。,3. **本地化运行:** 所有数据处理在本地完成,确保隐私和数据安全。,4. **AAAK语言:** 专属缩写语言减少tokens,适合资源受限但需准确率高的场景。,5. **实时纠错:** 使用fact_checker.py自动校验信息一致性,提高系统可靠性。,**安装与使用:**,1. **安装:** 通过pip安装MemPalace,简单易行。,2. **初始化:** 创建记忆宫殿,数据存储在本地目录。,3. **数据挖掘:** 三种模式处理项目、对话和通用内容。,4. **使用模式:** 自动模式适用于AI工具,手动模式适合本地模型。,**团队背景:**,由Milla Jovovich(演员)、Ben Sigman(程序员)和Claude共同开发,结合人类和AI的优势,旨在帮助开发者更好地利用已有知识,促进创造力。,**项目成果:**,- 在GitHub上迅速获得大量星星,显示出强劲的社区支持。,- 开源且免费,吸引了广泛关注,尤其是AI和开发者群体。,**展望:**,MemPalace在AI记忆系统领域具有潜力,尤其在结构化信息管理和高效检索方面,未来可能会扩展更多功能和优化性能,以适应更复杂的应用场景。,****,MemPalace不仅展示了AI在记忆管理中的潜力,也体现了跨界合作的力量,它通过创新的结构化方法,为信息管理和检索提供了新的解决方案,对AI发展和应用有重要贡献。
(来源:量子位)
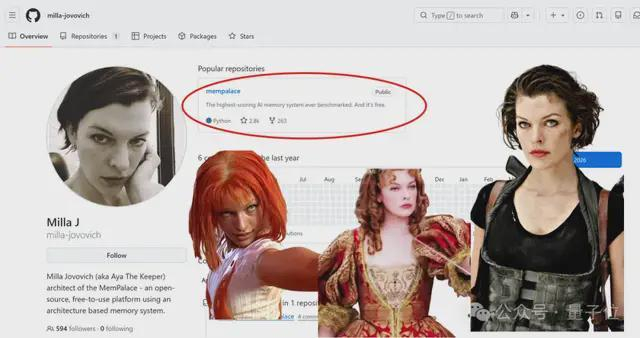
起猛了,在GitHub刷到《生化危机》女主角的项目了!
Milla Jovovich,这位曾饰演爱丽丝的知名女星,最近和程序员老友及Claude一起,合造了一个AI记忆系统。
这个系统历经几个月打磨,一亮相便在长期记忆基准测试LongMemEval中拿下“公开可查史上最高分”96.6%。
而且发布即开源,所有人免费可用(注意还是本地可跑)。
当然,比成绩更有意思的,还是项目背后的设计思路:
就像它的代号MemPalace一样,这个项目以古希腊演说家惯常采用的“记忆宫殿法”为灵感来源,让AI通过“空间位置”来组织记忆——
Palace是包含所有知识的大房间、不同知识按主题放在不同Rooms中、每间房里储存着具体的Memories。
想要检索某样东西,就像在房间里行走,推开一扇扇门一样。
凭借这种记忆结构,MemPalace的检索效率相比全局乱搜提高了约34%。
更重要的是,为了解决AI记忆难题,以前人们都在卷“让AI决定什么更值得记忆”,现在却不需要了。
更更有意思的是,他们还专门给AI造了一种缩写语言AAAK。
用上“记忆宫殿”,检索提升34%
来看更多MemPalace的信息。
在另一位作者Ben Sigman的形容中,和市面上已有的AI记忆系统相比,MemPalace的独特之处在于:
一是成绩最好,二是工作方式截然不同。
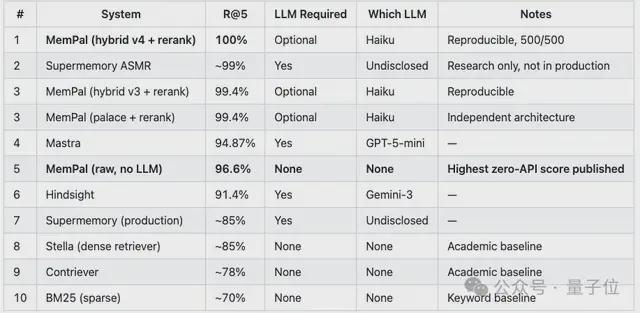
除了在LongMemEval中(RAW模式)拿到史上最高分,它还在ConvoMem(侧重考短期记忆)和LoCoMo(侧重考几个月超长记忆)上分别斩获92.9%和100%的好成绩。
Ben甩出的部分测评成绩如下(任何人均可根据仓库提供的脚本进行测试):
需要注意,MemPalace不会将用户数据发送到云端,所有记忆处理都在本地完成。
这也从源头上降低了隐私泄露的风险——因为不论是对话内容的记录、结构化整理,还是后续的检索与调用,都不依赖远程服务器。
不止本地化,MemPalace还用上了“记忆宫殿法”这种类人记忆模式。
和常见的向量数据库方案不同,MemPalace并不是简单把对话切片、Embedding,然后做相似度召回。
其核心在于,把记忆变成一个可导航的空间结构。
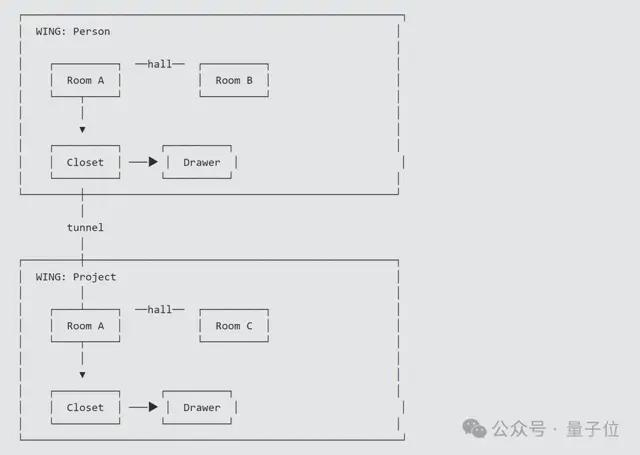
其中Wing(翅膀)代表一个人或一个项目,每一个展出去的翅膀都相当于一个独立空间。
这个独立空间中有很多Rooms,每一间Room代表一个具体主题(如认证、计费、部署等),所有信息将按主题归到不同房间。
连接不同房间的是Halls(走廊),它主要定义“这段记忆属于哪一类”(如建议、个人偏好、决策等),在主题之外给信息加上各种属性。
具体内容则分成两层存储:
抽屉(Drawers)里放原始记录,所有对话一字不动,完整封存;
衣柜(Closets)则放这些内容的压缩摘要,为AI快速读取而准备。
而当不同翅膀出现了相同的房间时,MemPalace就会自动打通Tunnels(隧道),以把分散在不同人、不同项目中的同一主题连接起来。
最终,在这套结构下,所有内容都可以在记忆宫殿里按路径查找。
这里作者还搞了两个实验验证了两件事:
关于结构有多大作用,作者在22000多个真实对话中,直接对比了4种检索方式的效果:
全局乱搜、先限定在某个翅膀、再加一层走廊、再精确到房间。

结果发现,每多一层结构,就相当于缩小一次搜索空间以及增强一次语义约束,所以效果也越来越好。
在作者看来,宫殿结构本身,就是产品。
至于什么时候找、找多少这类效率问题,作者则设计了一套重要程度由轻到重的记忆堆栈。
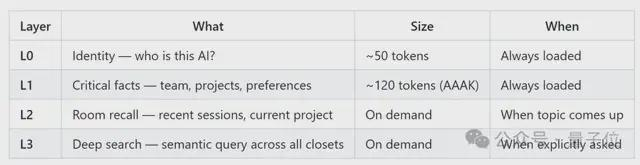
其中L0+L1属于“常驻选手”,总计约170 tokens,会在每一次对话中始终加载,让AI在“醒来”的那一刻,就已经具备最基本的自我认知和用户上下文。
L2、L3则按需触发,前者属于房间级召回,后者属于全局深度搜索。
整体逻辑是,先用最小成本理解你,不够再局部补充,还不够才全局搜索。
这样设计带来的好处也很直接,不仅单次召回更准,而且长期记忆也更稳定了。
而说到长期记忆,作者也直接给MemPalace扔了6个月的对话内容,大约有1950万个tokens。
简单换算一下,这相当于200~400本书,又或者一个拥有10~30个项目的中型代码库。
如此大体量,传统方法就不指望了(基本无法全部塞进上下文)。
用总结压缩的话,通常能压到65万tokens,年成本大约507美元(约合人民币3500多元),不过过程中往往会丢失信息。
而用MemPalace,平时仅需加载约170个tokens,按需加载也才13500个tokens,年成本直接砍到10美元,并且也不牺牲信息细节。
在这个意义上讲,MemPalace确实和传统记忆系统已经不在一个level了。

而MemPalace能做到信息准确的关键,作者也透露了两点。
一个就是我们开头提到的AI专属语言“AAAK”——不需要额外解码器,主流大模型都可以直接理解。
因为大模型本质是“读token模式”的,废话越少、关键信息越集中,它反而看得更清楚。
尤其在表达大量重复实体时,AAAK能明显压缩token。
不过作者也说了,LongMemEval上AAAK模式的召回率是84.2%,而RAW模式是96.6%——差了12个多点。
所以,想保精度就老老实实用RAW模式,想省token且能接受一定信息损失再上AAAK。
另一个则是实时纠错,通过一个叫fact_checker.py的独立工具实现(集成中)。
未来上线后,遇到前后信息相互矛盾,MemPalace就能在生成结果前自动做一致性校验。
而当MemPalace同时把长期记忆和准确性都兼顾下来,也就不难理解作者为什么敢喊出“当前最好的记忆系统”这样的口号了。
插一嘴,它的Logo也像一个简易版宫殿:

如何安装部署?
具体安装步骤和两种使用模式如下。
第一步:在终端中运行以下命令,通过pip安装MemPalace。
pip install mempalace
第二步:初始化世界,创建一个属于你的记忆宫殿(以下命令会设置一个存放你所有记忆数据的主目录)。
mempalace init ~/projects/myapp
第三步:挖掘数据,把你的项目文件、聊天记录等喂给MemPalace,让它建立索引。
根据数据类型,有三种模式可选:
(1)挖掘项目:适用于代码、文档和笔记。
mempalace mine ~/projects/myapp
(2)挖掘对话:适用于Claude、ChatGPT、Slack等导出的聊天记录。
mempalace mine ~/chats/ —mode convos
(3)通用挖掘:自动将内容分类为决策、里程碑、问题等。
mempalace mine ~/chats/ —mode convos —extract general
完成这三步,你的本地记忆宫殿就搭好了,所有数据都存储在本地,不会上传到云端。

接下来就是如何使用了。
一个是自动模式,适用于支持MCP工具调用的AI,只需一次连接即可:
claude mcp add mempalace -- python -m mempalace.mcp_server
连接完成后,AI就会自动调用MemPalace的检索工具。
另一个是手动增强模式,主要配合本地模型使用。
如果只是平时用用,用以下命令加载基础记忆即可(触发词,170个tokens)。
mempalace wake-up > context.txt
如果还有更多需求,则可以通过命令行按需检索相关记忆,并将结果手动注入到提示词中。
mempalace search "auth decisions" > results.txt
这里不想手动的,还可以使用Python API,直接在代码中完成检索与注入。
from mempalace.searcher import search_memoriesresults = search_memories("auth decisions", palace_path="~/.mempalace/palace")
天啦撸,在GitHub看见女明星了!
最后简单介绍下MemPalace的团队:一个架构师+一个程序员+Claude。
架构师我们很熟悉,就是开头提到的女明星Milla Jovovich,她贡献了很多经典荧幕形象。
除了《生化危机》系列中的爱丽丝,她还饰演了知名科幻电影《第五元素》中的外星人leeloo、动作电影《三个火枪手》中的德文特夫人……

wait wait,你是说这样一位以演员身份示人的女明星,如今却和AI记忆系统挂上钩了吗?
只能说,虽然很反差,但事实确实如此。
而且通过Milla Jovovich的自述,她的这种跨界很早就开始了。
据悉,她私下一直在做一个大型游戏项目,但过程中遇到的一系列问题,让她意识到:
如何管理和利用信息,本身可能比项目更重要。
于是她找到了自己相识20多年的老朋友——资深程序员Ben Sigman,决定研究一下这个问题。

直到6个月前,Ben给她讲了Claude Cli,于是她很快意识到:
对于一个热爱写作的创作者来说,AI已经可以把想法直接转化为可运行的系统。
于是“一个架构师+一个程序员”的组合就此成形。
在Milla Jovovich看来,当下AI的核心问题在于它只能基于已有信息工作,而真正的创新来自人类的想象力与持续探索。
也正因如此,她和Ben希望通过开发MemPalace这样的系统,可以帮助开发者更好地利用已有知识,从而创造新的东西。
目前MemPalace在开源社区的热度正在飙升中,周二下午17:00看还只有3.3k star,现在已经飞涨至17.4k。
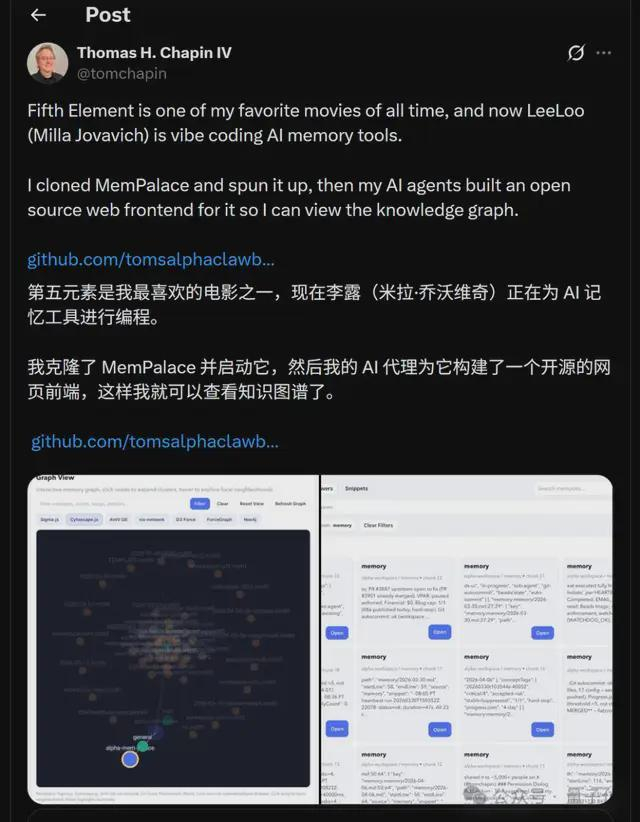
而且手快的网友已经给它做了一个前端:
GitHub:
https://github.com/milla-jovovich/mempalace
 admin
admin